2021. 7. 15. 11:22ㆍmongodb
금일은 Mongodb 랑 Spark하는 방법에 대해서 알아보겠다.
2020년 Mongodb에서 Spark 3.x 지원을 하기 시작했다.
2020년 7월쯤 Spark 3.x 으로 먼저 업그레이드를 한 뒤...
Mongodb에서 Spark 3.x를 지원하지 않아서 멘붕에 빠진적이 있었다.

하긴 Spark 3.0이 6월 18일이니까, 너무 바로 다음달 7월에 적용한다는게, 지금 생각해보면 무리였다.

당시 나온 Spark 3.0은 소개글이다.
Spark3.0이 Spark 2.4 대비 성능이 2배이상 차이가 난다.
그래서 아무생각 없이 무조건 업그레이드를 해야겠다고 생각했다..
결국 그 생각이 화근이 되어 당시 Spark3.0 를 업글은 없던 일이 되었다..
그 후, 한달 뒤, 2020년 8월쯤에 해당 서비스를 Mongodb에서 공개했다.
진짜 조금만 빨리 나와주지..
( Mongodb 에서 2달만에 나온거니, 그렇게 늦은것도 아니다. ㅠ-ㅠ )
그럼 python으로 샘플 코드를 한번 짜보겠다.
1. Spark Session를 만들어 준다.
| from pyspark.sql import SparkSession spark = SparkSession\ .builder\ .master('local')\ .config('spark.mongodb.input.uri', 'mongodb://xx.xx.xxx.xx/database_name.collection_name')\ .config('spark.mongodb.output.uri', 'mongodb://xx.xx.xxx.xx/database_name.collection_name')\ .config('spark.jars.packages', 'org.mongodb.spark:mongo-spark-connector_2.12:3.0.1')\ .getOrCreate() |
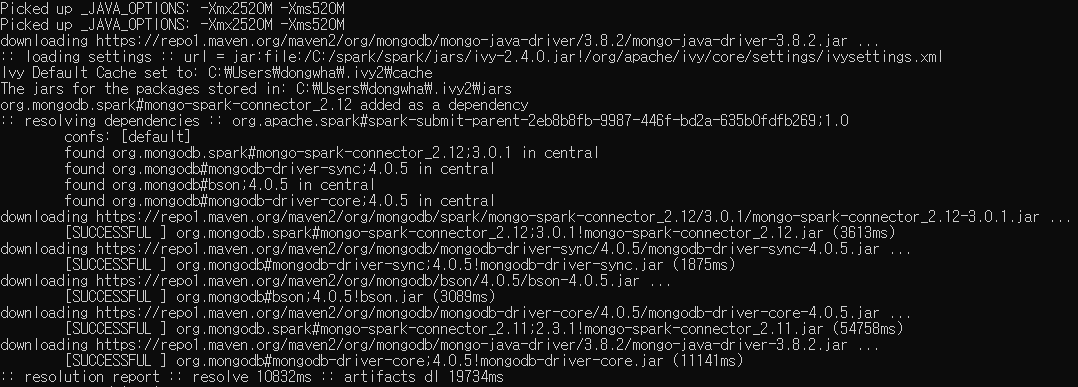
2. [1. park Session를 만들어 준다.] 위에 굵게 칠해진 부분을 넣어주면, 아래와 같이 mongo-spark가 다운받아진다.
- mongodb spark connection이 maven으로 다운 받아지는 걸 확인 할 수 있다.
3. 데이터를 load 한다
- 이렇게 올리면, 전체 collection 데이터가 다 올라간다.
| df = spark.read.format('mongo').load() |
- 뭐 다들 알겠지만, 다음과 같이 하면 mongodb 쿼리도 입력이 가능하다.
| filter = [ {eventdtm : '202007080000' } ] df = spark.read.format("mongo").option("pipeline", filter).load() |
4. 데이터 확인한다.
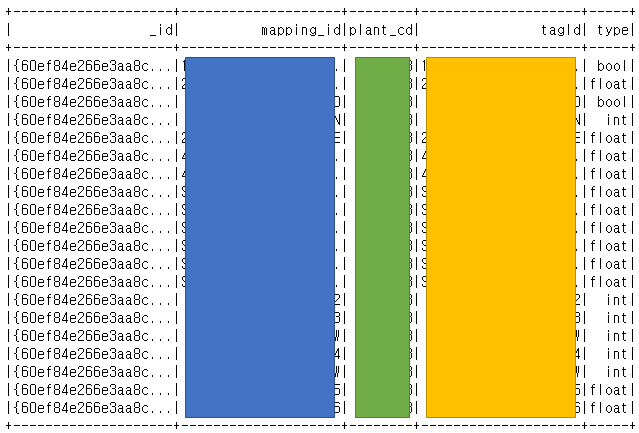
생각보다 쉽게 되었다 ㅎㅎ
하지만,, 나는 삽질을 한시간 했다는건 안 비밀....
그럼 이만 ~!
'mongodb' 카테고리의 다른 글
| mongodb group by 샘플 (0) | 2023.03.09 |
|---|---|
| MongoDB TTL 설정 ( 데이터 자동 삭제 스케줄 ) (1) | 2022.09.08 |
| Mongodb Shard 추가 및 주의사항 (0) | 2021.04.22 |
| mongodb shard 제거하기 ( remove ) (1) | 2021.04.22 |
| 몽고디비(mongodb) 샤드(shard) 설정 (0) | 2021.04.19 |