DataLake 의 이해 및 필요성 ( AWS 기반 설명 )
2023. 3. 9. 07:41ㆍit
반응형
1 데이터 레이크의 필요성

- 데이터간의 폐쇄성으로 데이터 통합이 필요함
- 기존 DW 보다 더 거대한 통합을 원함
- 레거시 시스템들의 분산으로 통합 데이터의 필요성이 대두됨
2. 데이터 폐쇄성으로 인한 문제

- 데이터의 비용 증가
- 정확도 저하
- 중북 증가
- 협업의 감소가 발생
3. 데이터 레이크의 배경

- 다양한 데이터로 인한 한계
- 분산된 저장소로 인한 한계
- 식상해 보일 수도 있지만, 빅데이터를 활용하기 위한 저장 방법론이 필요하게 됨

공공재 개념의 데이터가 필요해짐

데이터를 융합을 의한, 데이터 활용을 위한, 데이터의 저장소를 만들 필요가 생김
4. 그럼 어떤 요소로 한계를 극복했는가? ( 클라우드 개념에서 )

- 저렴한 저장소가 필요하게 됨
- 클라우드가 저렴해?
- YES? NO?
- YES : 사용할 만큼 비용을 지불해서, 저렴하다. 인프라 유지보수 시간을 비용으로 측정한다면 저렴하다.
- NO : 온프레미스로 구현하면, 클라우드 24시간 사용한거보다 저렴하다. 인프라 유지보수 인력이 있는데, 굳이 해당 비용을 줄일 필요가 없다.
- 그럼 DataLake를 24시간 사용하는가?
- YES : …….
- NO : 필요할때만 사용한다.
- YES? NO?
- 클라우드가 저렴해?
5. 데이터 레이크란 ?

6. AWS 가 설명한 데이터 레이크 구축의 허들
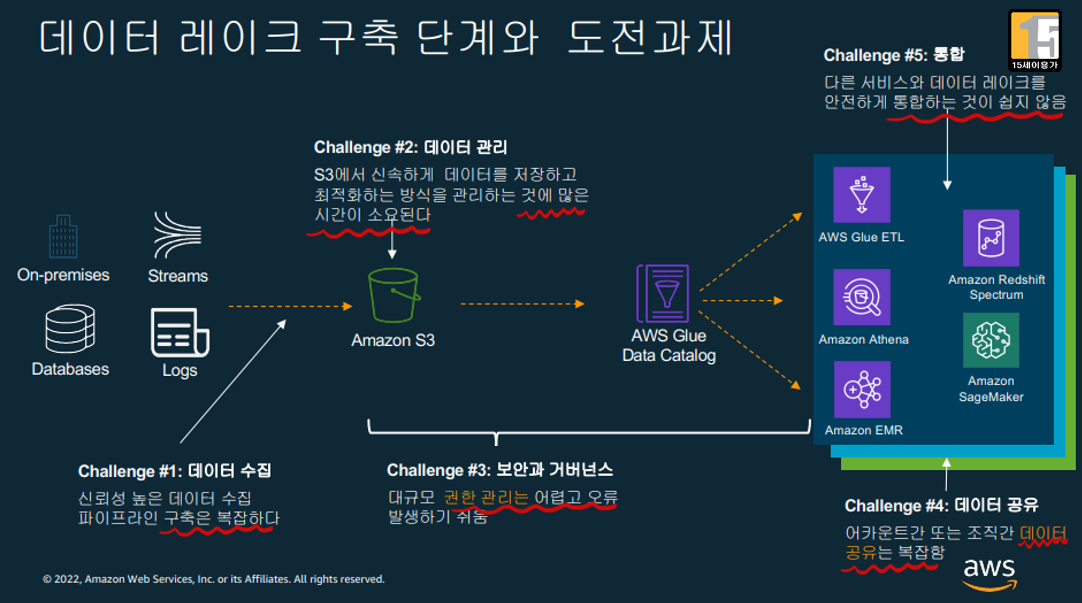
- 구축이 복잡함
- 권한 관리가 어려움
- 최적화에 많은 시간이 소요
- 통합이 어려움
- 데이터 공유가 복잡함
7. 데이터 레이크를 만드는 방법
- 낚시터를 만드는데에 비유해서 손쉽게 설명하겠음
7-1. 낚시터를 만들어 보자~!
- 데이터 레이크 구축은 낚시터의 공사하는 작업이라고 생각할 수 있음
7-2. 낚시터 공사 순서

- 소프트웨어 개발 방법론? ( 기분설개탱구유~!! - 대학교 전공 시험 출제 문제 )
- 기획 → 분석 → 설계 → 개발 → 테스트 → 구현 ( 배포, 적용 ) → 유지보수
문제1 : 데이터 레이크를 개발하기 위해, 먼저 수행해야 할 작업은 ?
답 : 기획 & 분석 ( 요구사항 분석이 필요함 )
- 데이터를 그냥 저장하면 쉬움, 하지만 추후 활용하는데, 어려움이 발생
- 그냥 저장하는 것은 쉽지만, 사용자가 활용하기 쉽게 만드는 작업이 어렵다!
- 그래서 요구사항 분석을 정확하게 해야 하며, 분석을 기반으로 설계를 쌓아 올려 만들어야 한다.

[가히 광고] “가장 사용하기 쉽다는 것이 가장 만들기 어렵다는 것”
7-3. 낚시터 개발을 위한 자원
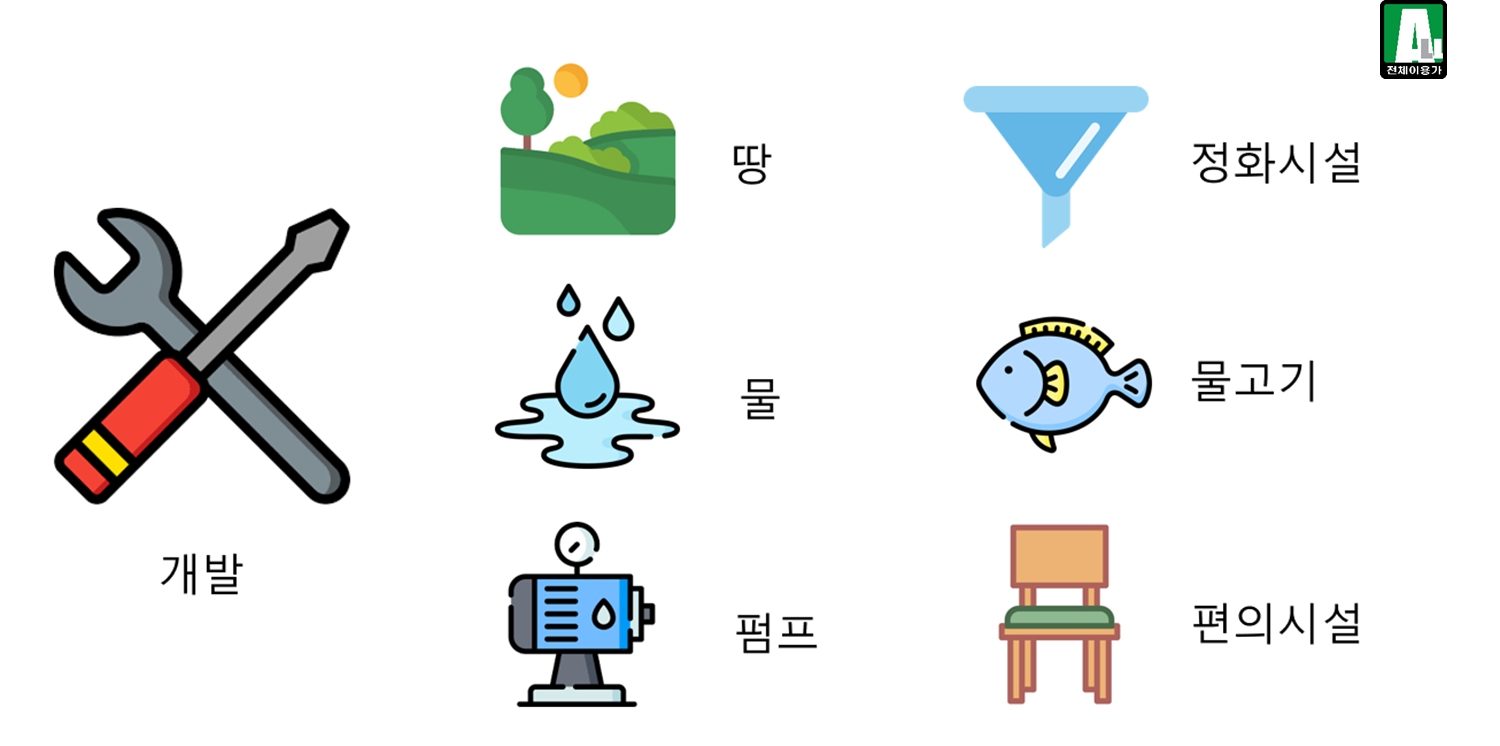
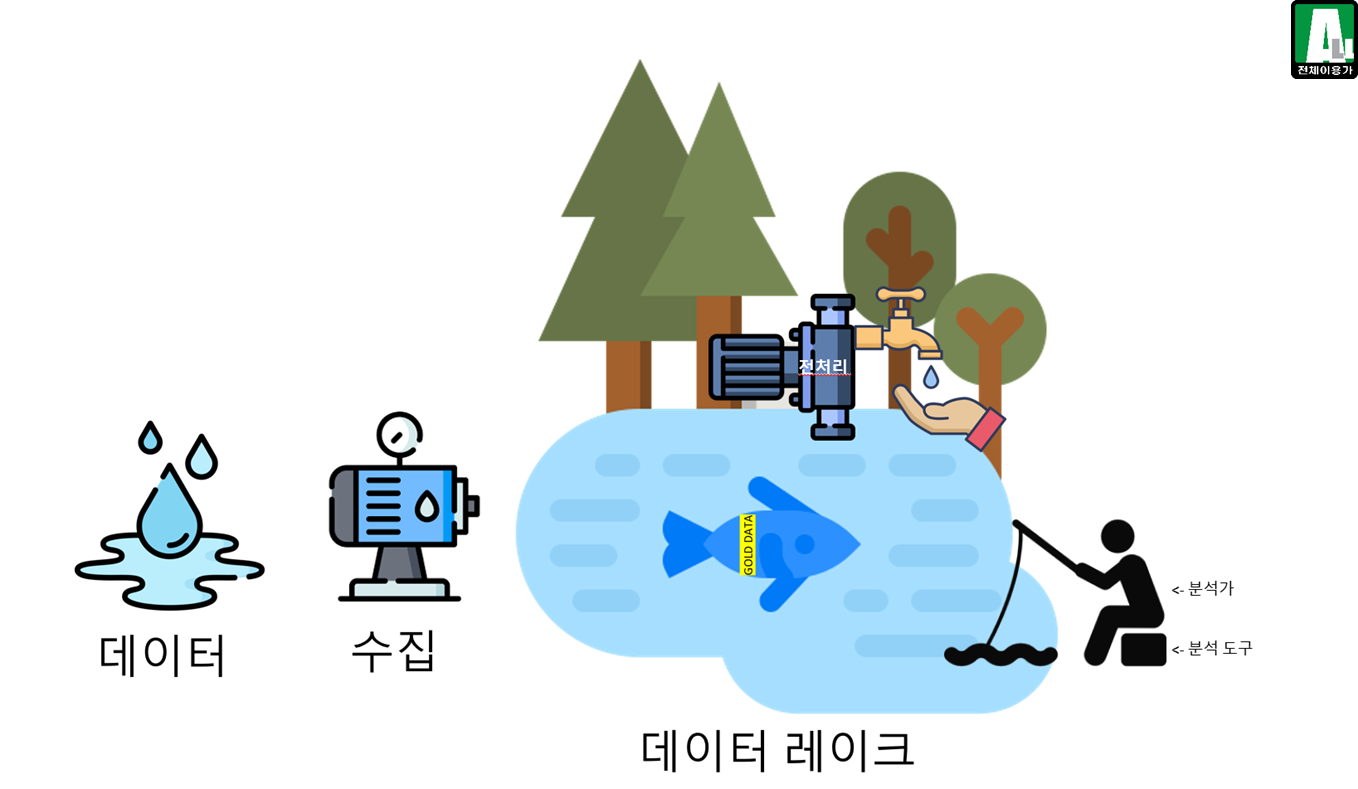
7-4. 개발이 완료된 낚시터의 모습
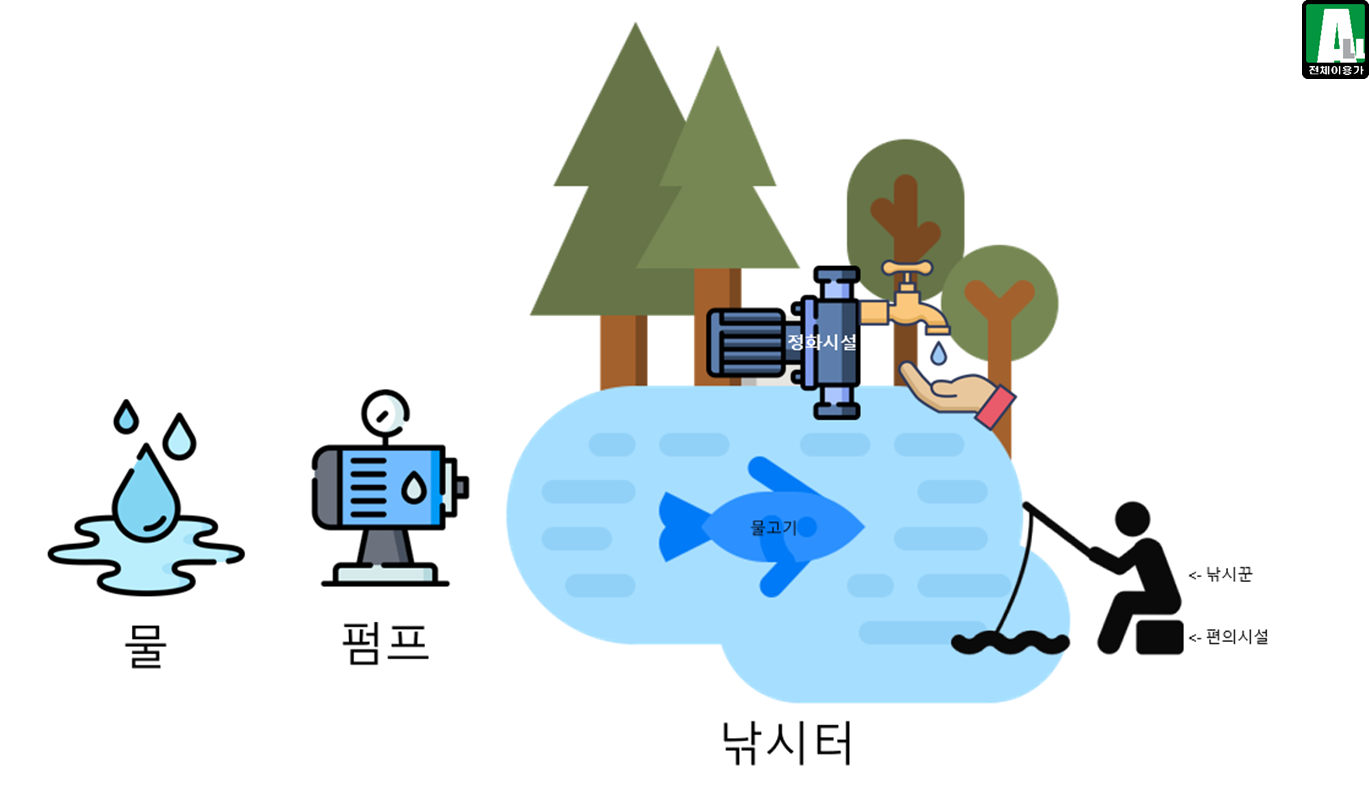
7-5. 개발 도구를 IT 기술과 매칭

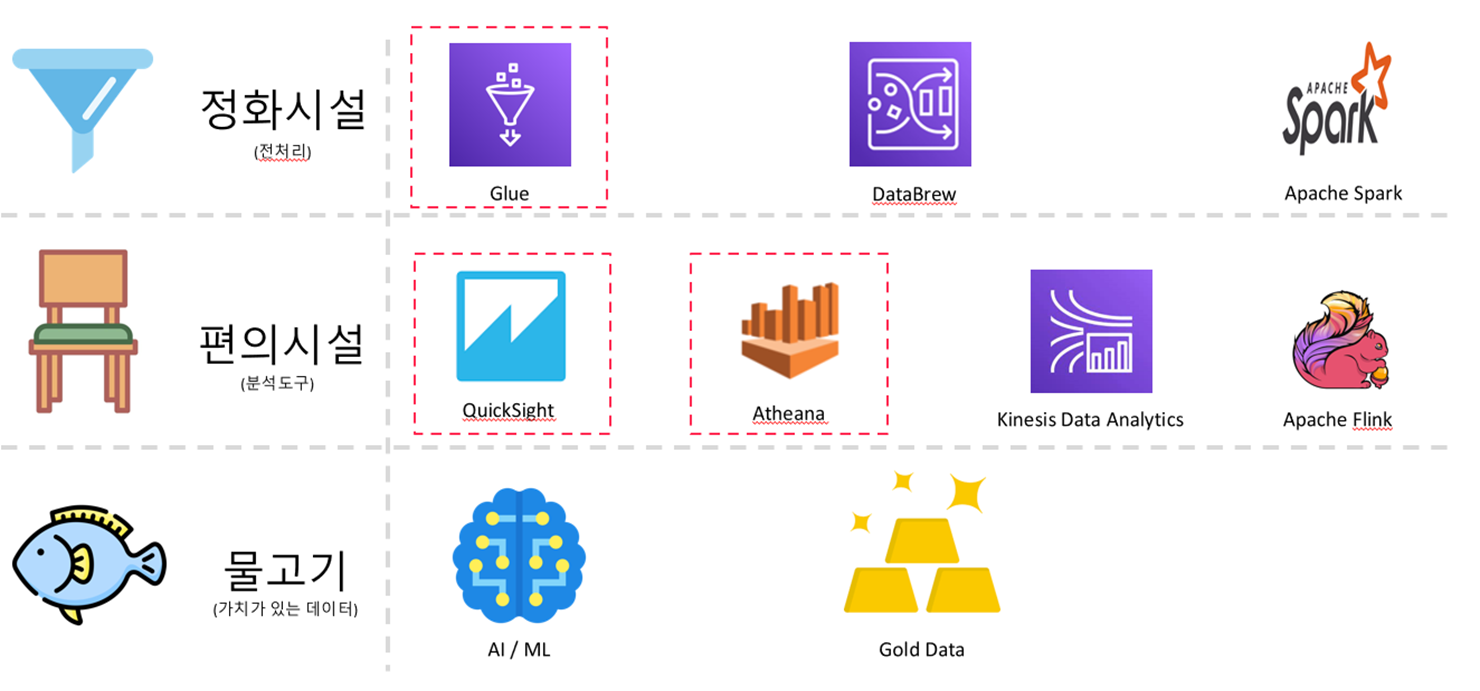
7-6. 낚시터를 IT 기술로 매칭
7-7. 낚시터를 IT 기술로 바꿔보기
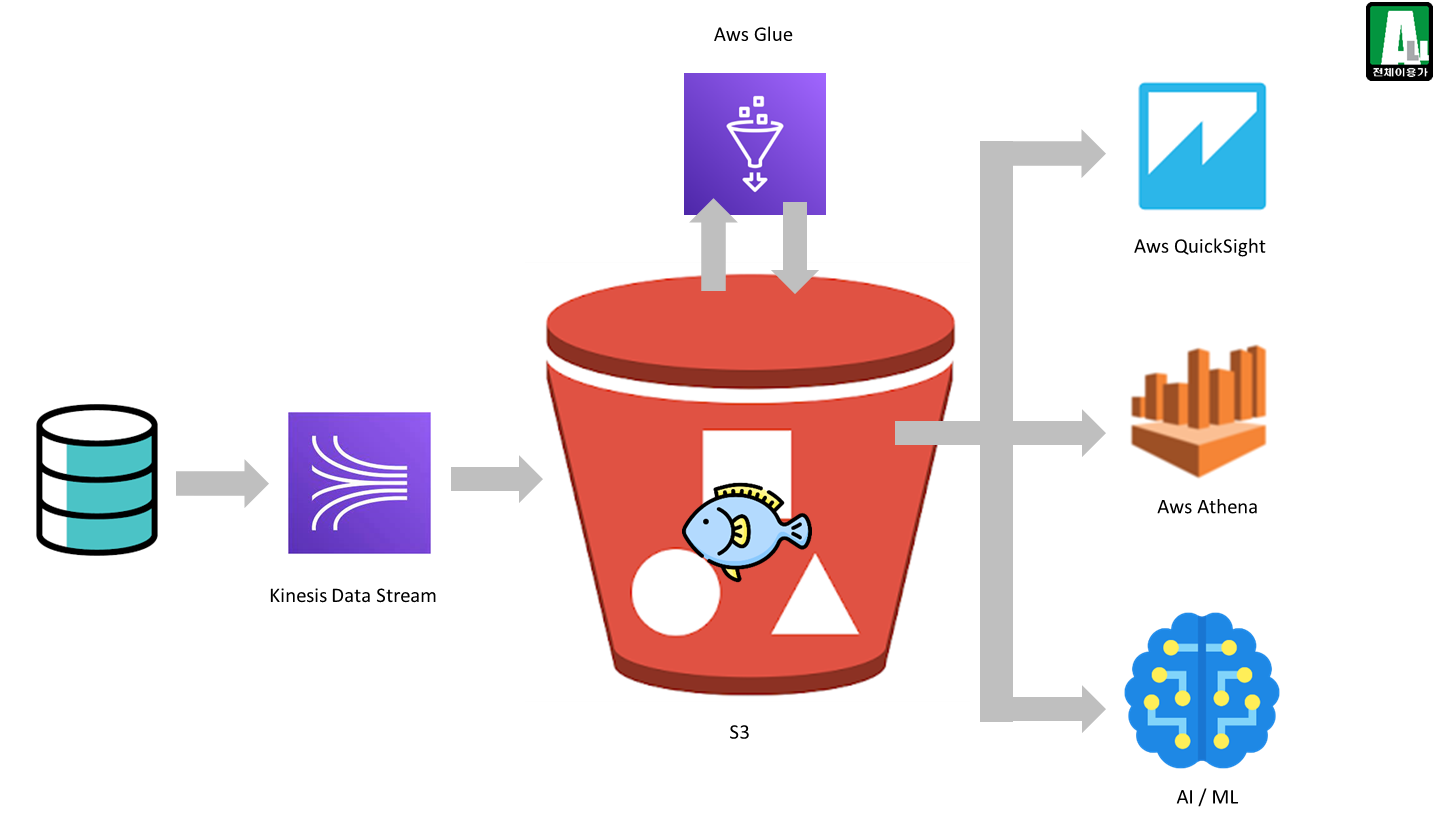
8. 결론

- 요즘 시장은 도구는 많음
- 같은 도구여도 누구는 훌륭한 집을 만들고, 누구는 두꺼비 집 만들기도 힘듬
- 즉, 도구가 중요한게 아님
- 도구보다는 설계가 중요함
- 각자의 화사에게 맞는 설계를 찾아야 함
- 하지만, 다른 회사의 설계했는지도 참고 해야함
- 왜?
- 코끼리가 어떻게 생긴지도 모르는데, 어떻게 그 코끼리를 그리겠는가?
- 각자의 화사에게 맞는 설계를 찾아야 함

반응형
'it' 카테고리의 다른 글
| Ubuntu 명령어 정리 (0) | 2023.03.14 |
|---|---|
| 오라클 아카이브 용량 에러 해결 방안 (0) | 2023.03.10 |
| AWS CDK Lambda & Athena (0) | 2022.04.26 |
| AWS AutoGluon 샘플( Tabular Prediction( 소득 예측 ) ) (0) | 2022.04.26 |
| AWS API Gateway Private Rest 만들기 (0) | 2022.04.09 |